Clients & Ventures
Product/systems design that turns AI tech into business results

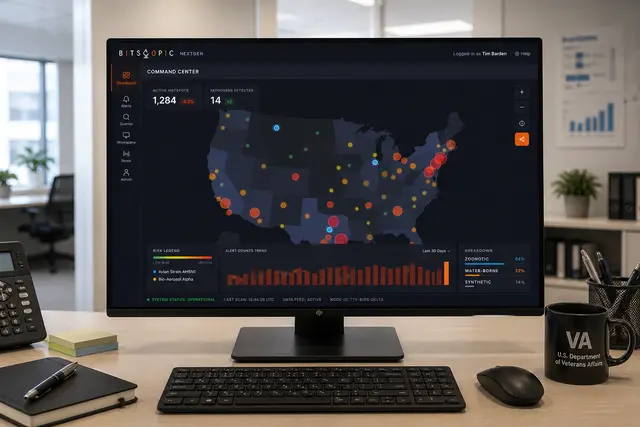



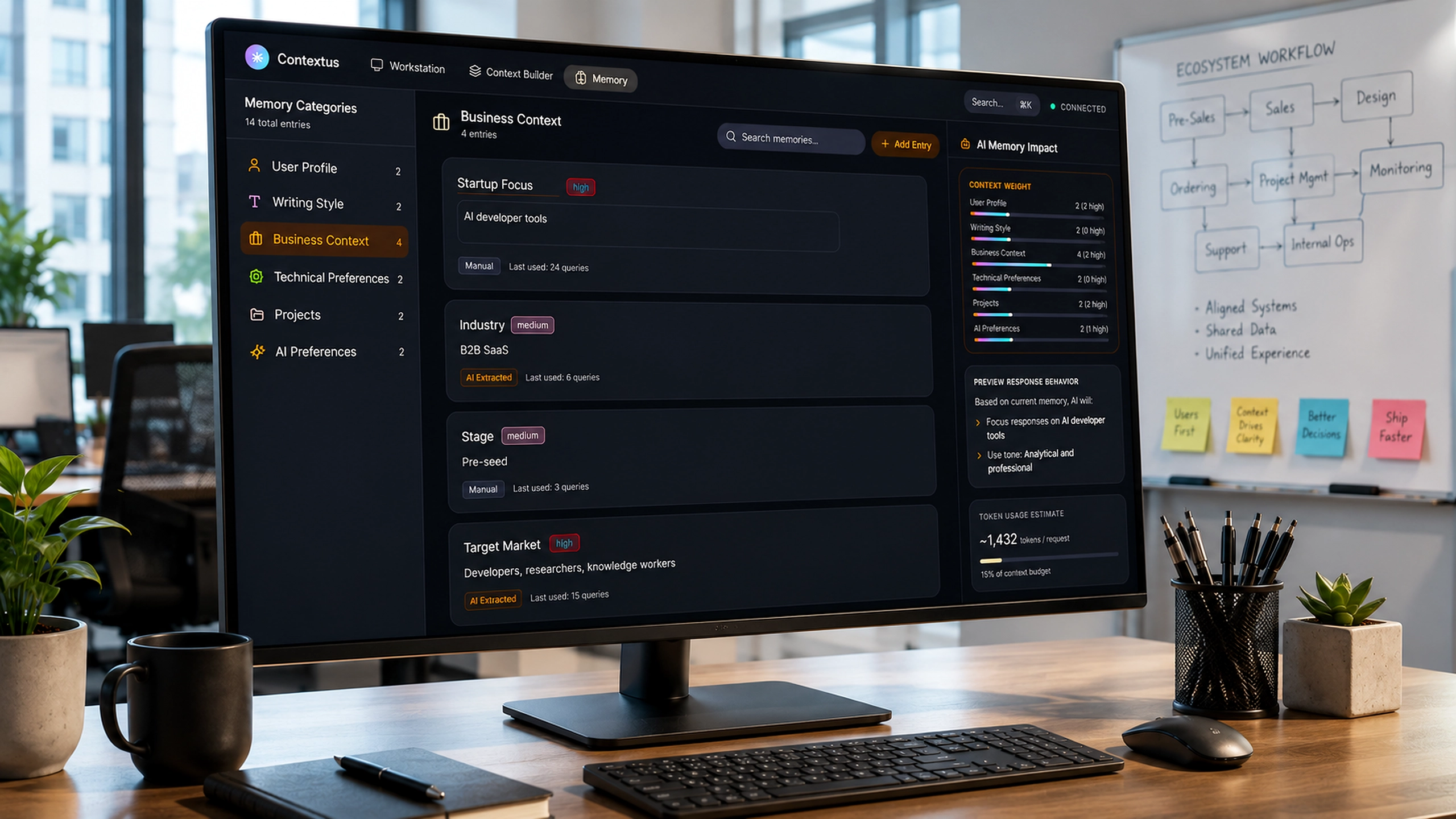









Contact Us
Contact form or information will go here.
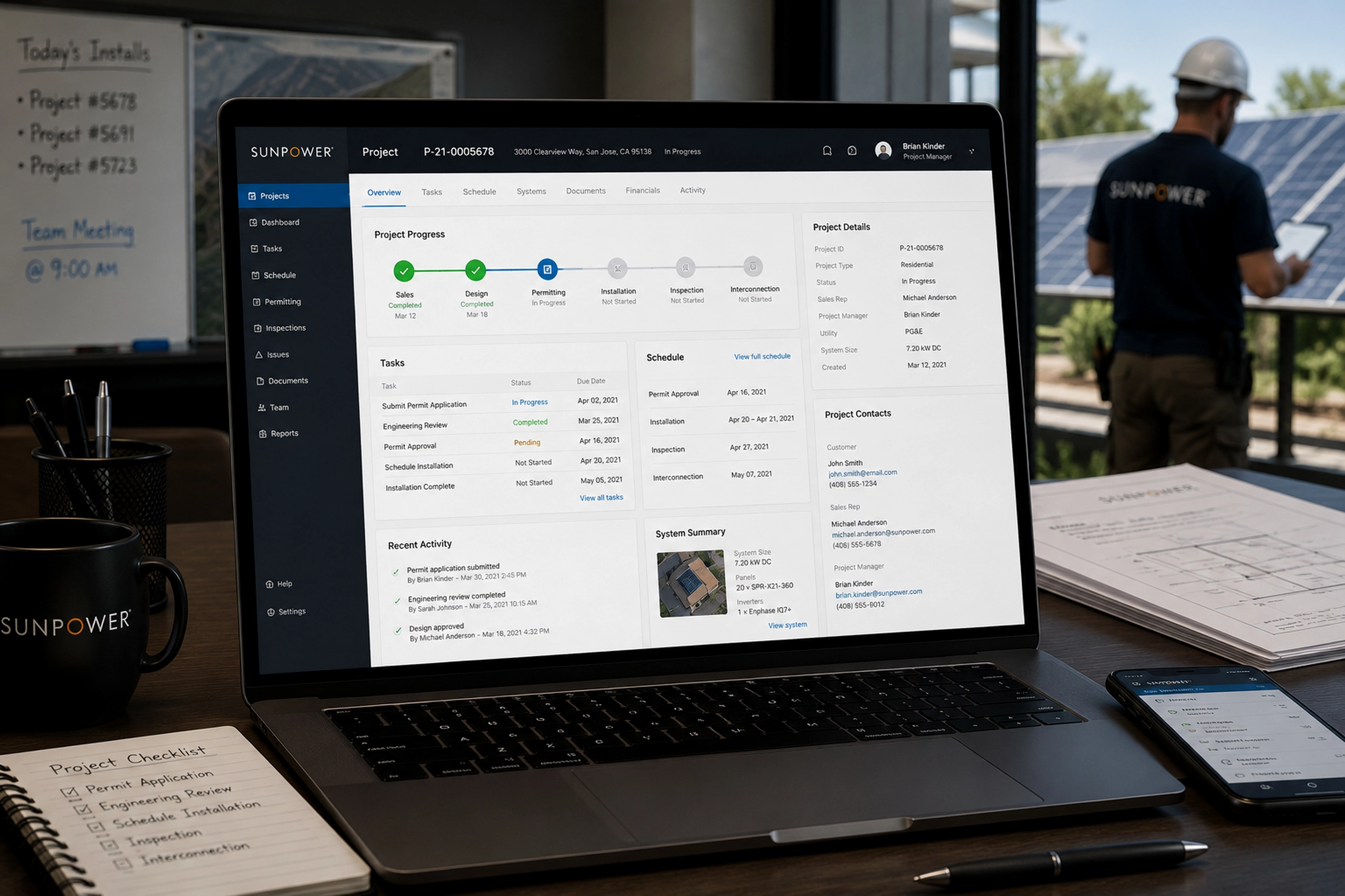
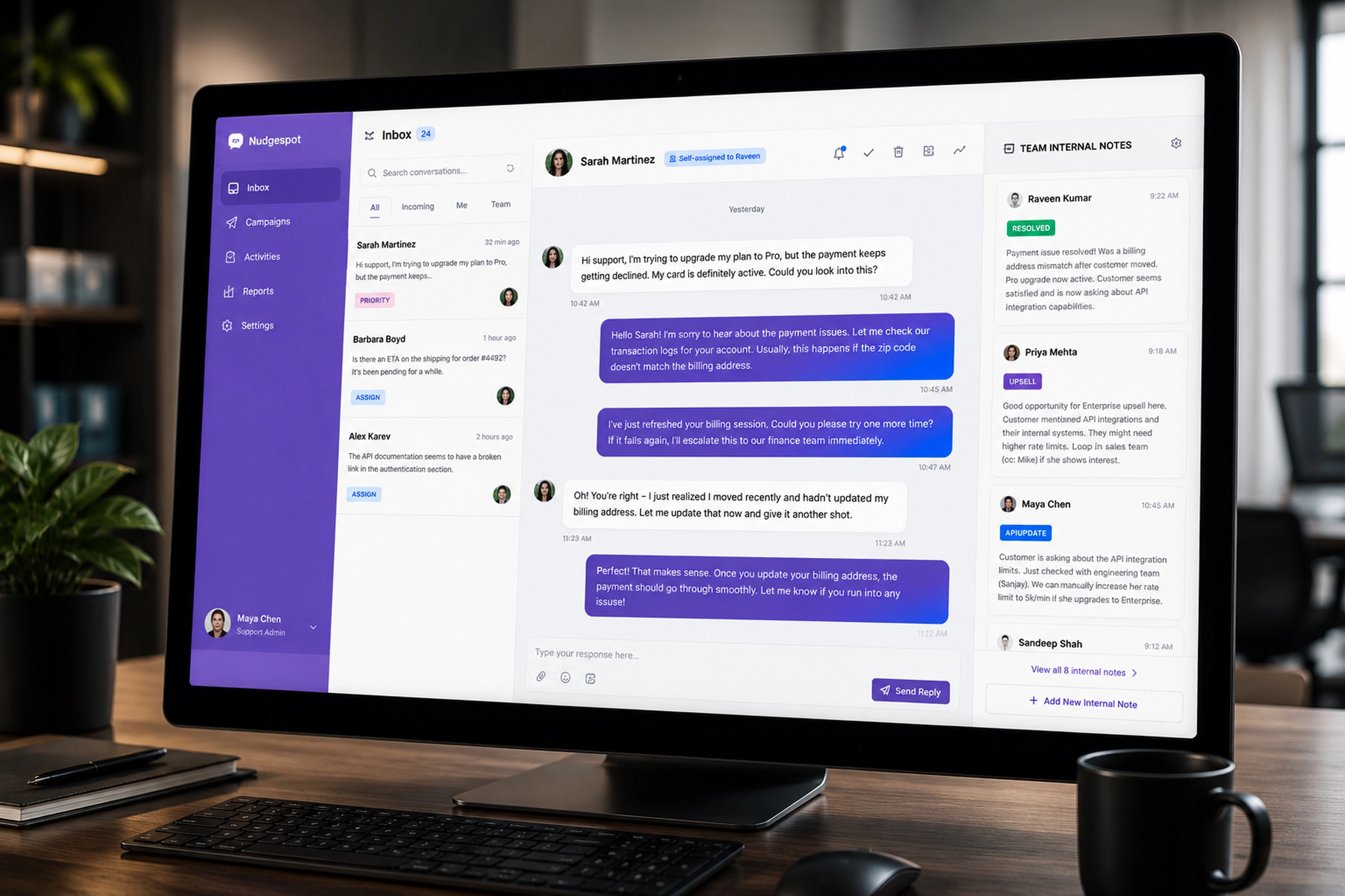
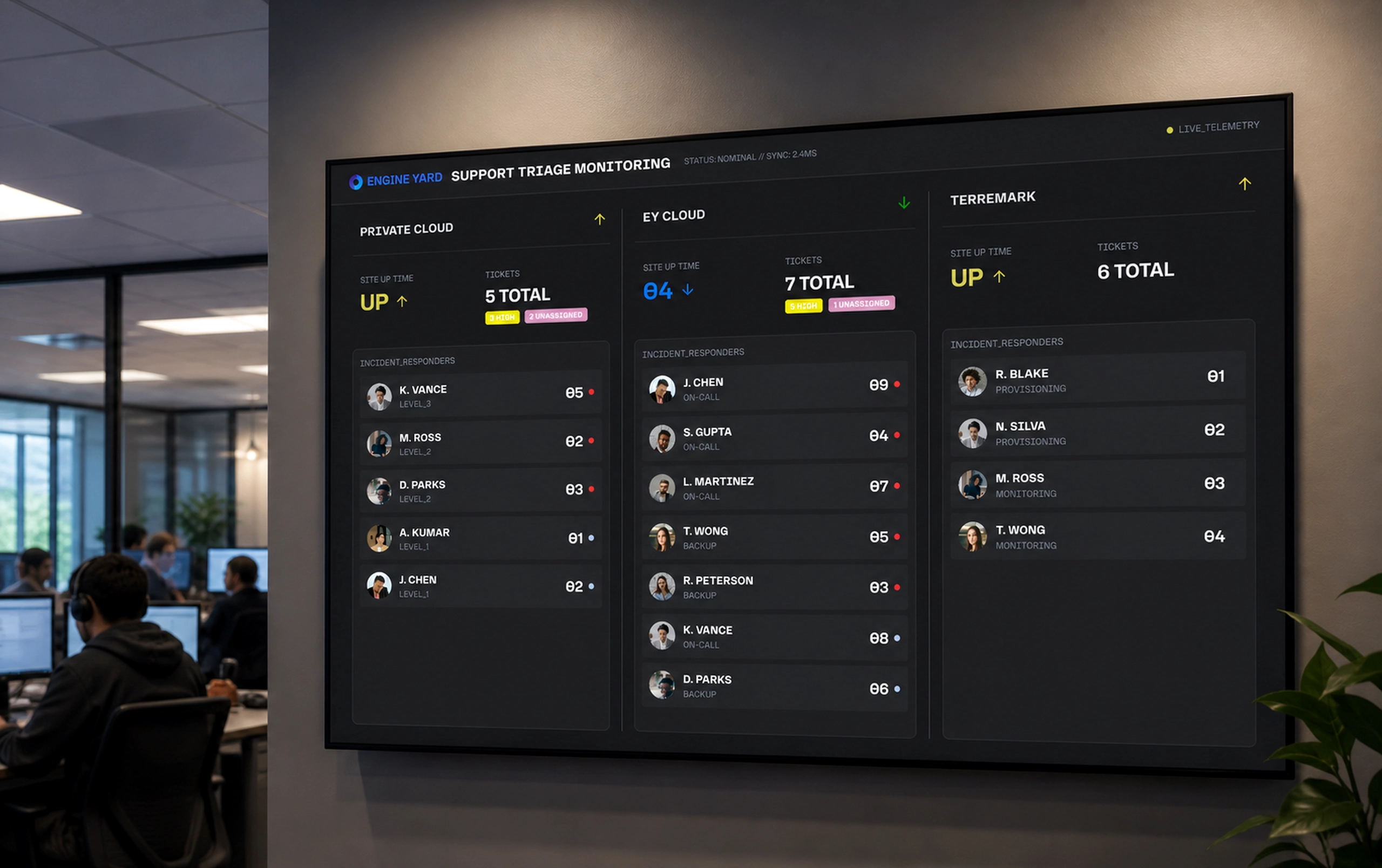
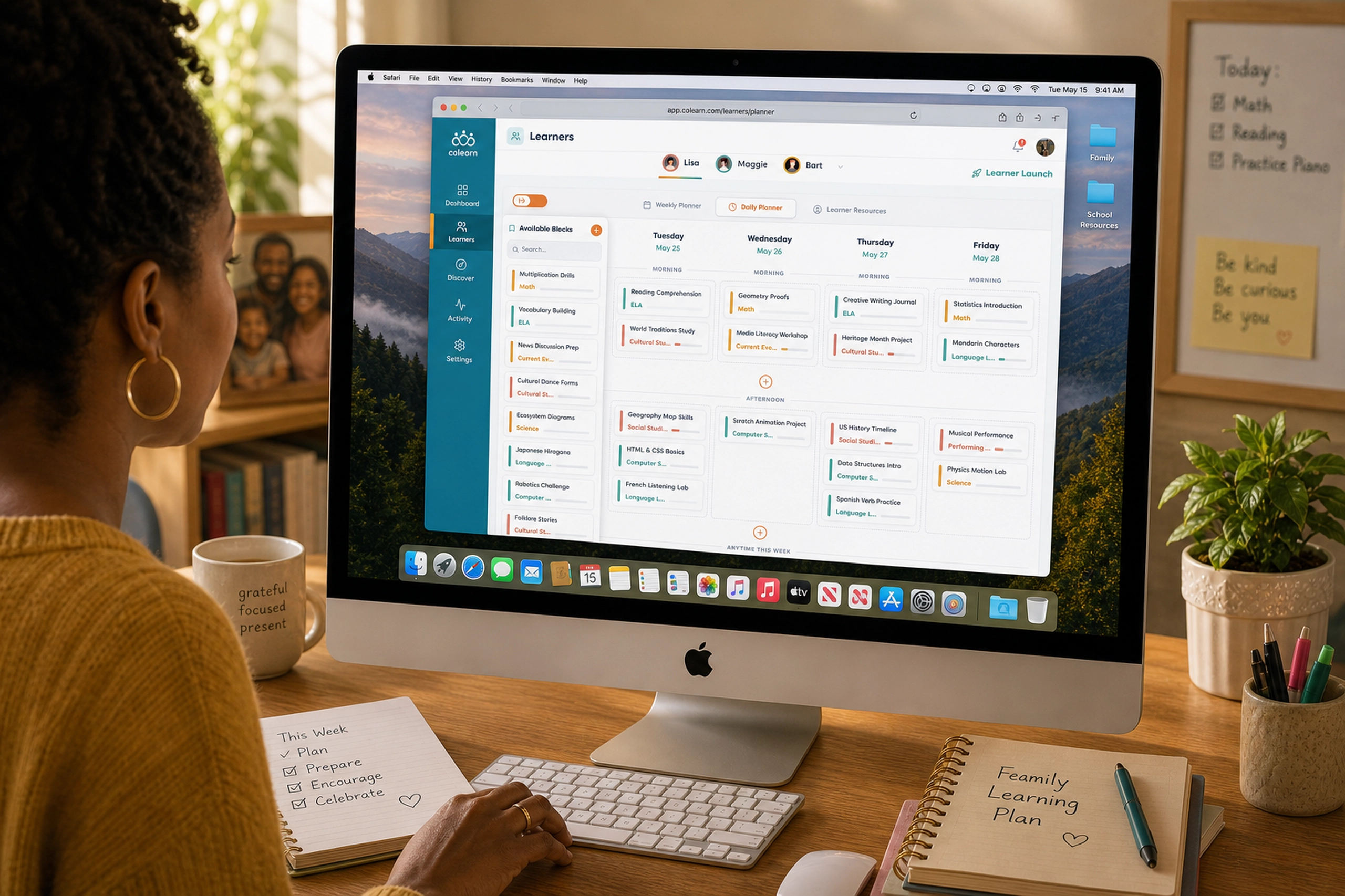
Project Detail
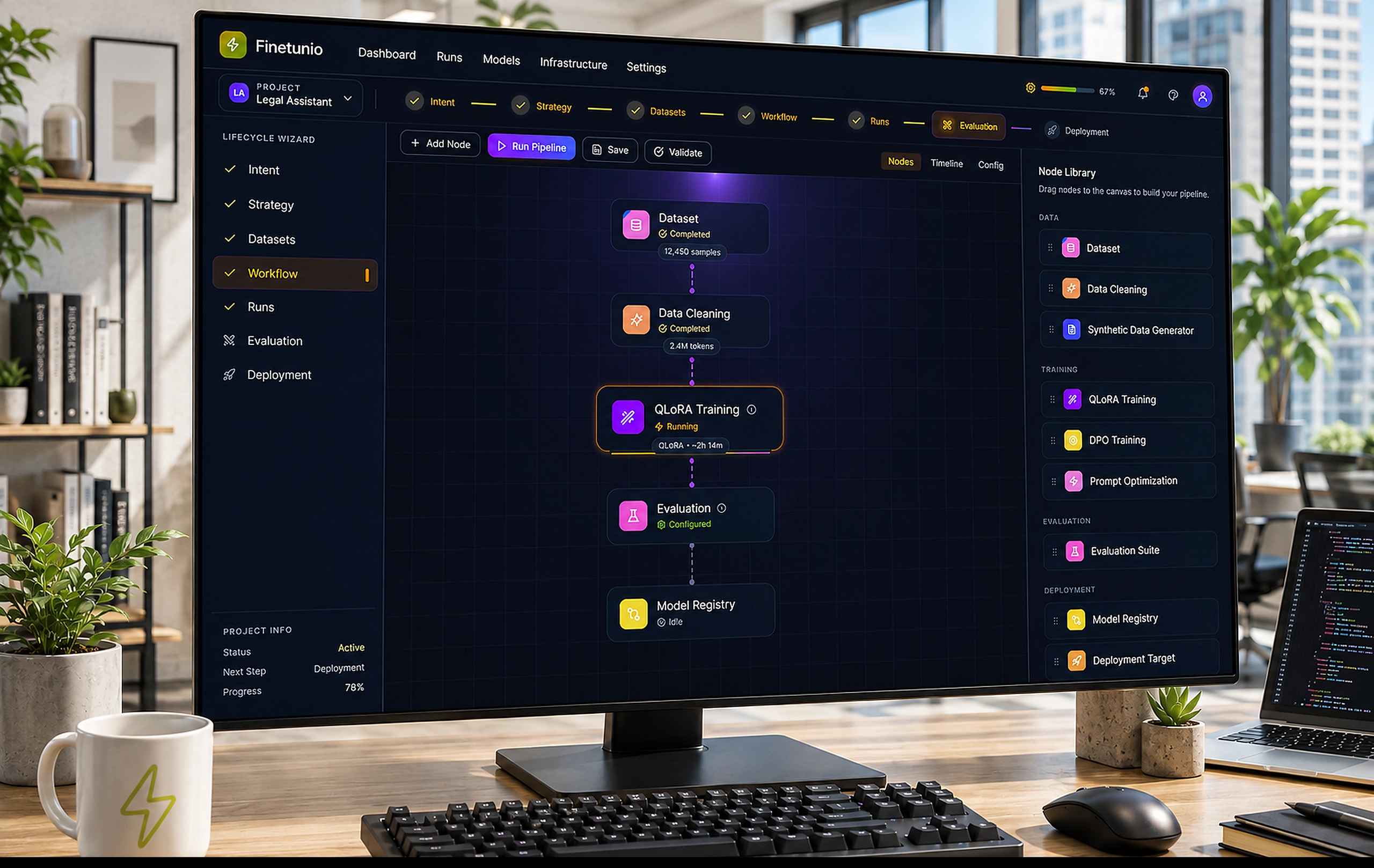
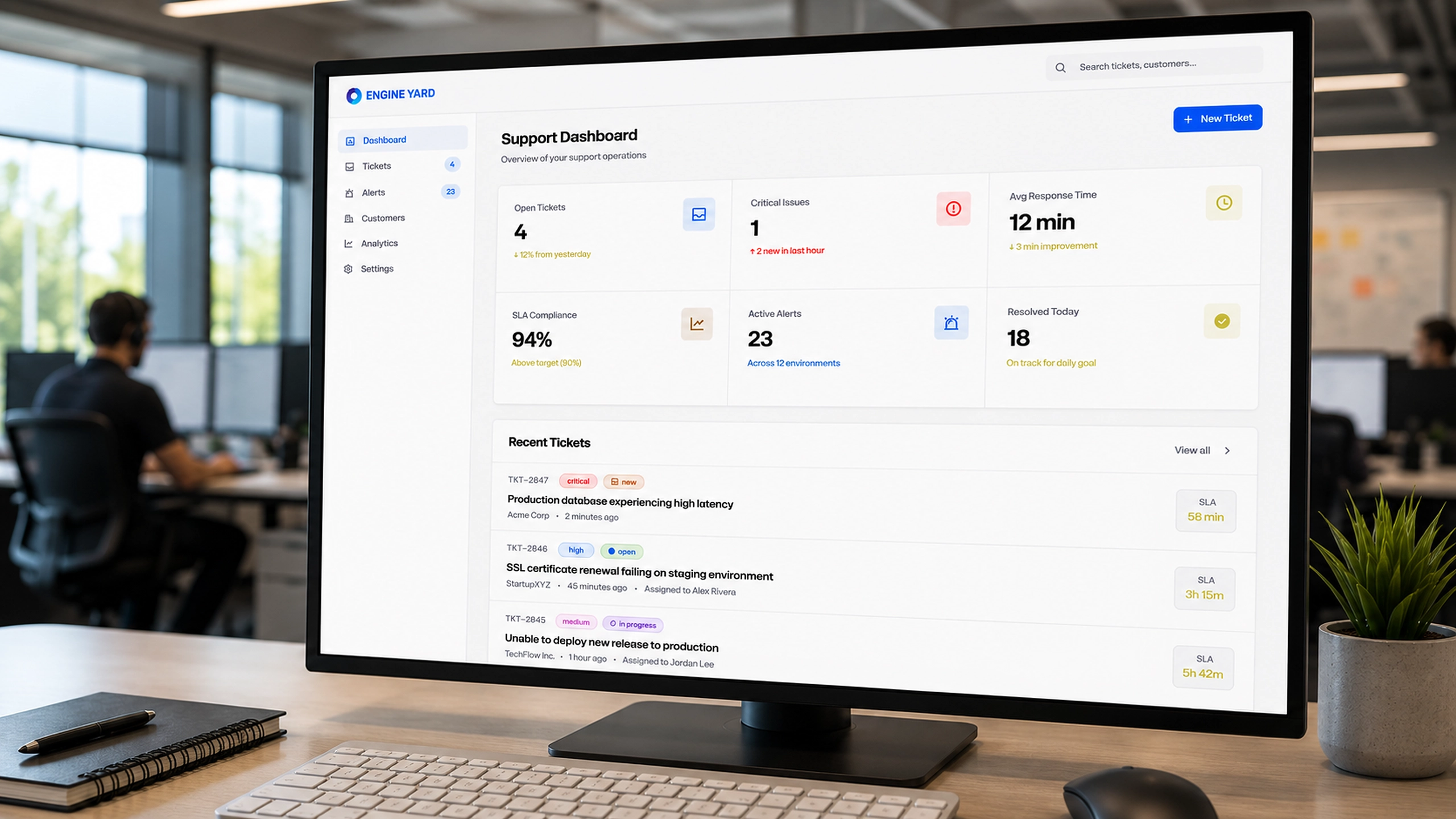
Finetunio - Model Optimization
Summary
An intent-first workbench for planning, executing, evaluating, and deploying model improvements.
Improving an AI model often means navigating disconnected scripts, datasets, training frameworks, evaluation tools, and deployment systems without a reliable way to decide what should happen first.
I designed Finetunio as a human-centered optimization workbench that turns behavioral intent into a connected path through strategy, data preparation, execution, evaluation, and deployment.
Outcome
A complete optimization story instead of a collection of technical steps.
Finetunio turned a fragmented model-improvement process into a coherent product lifecycle.
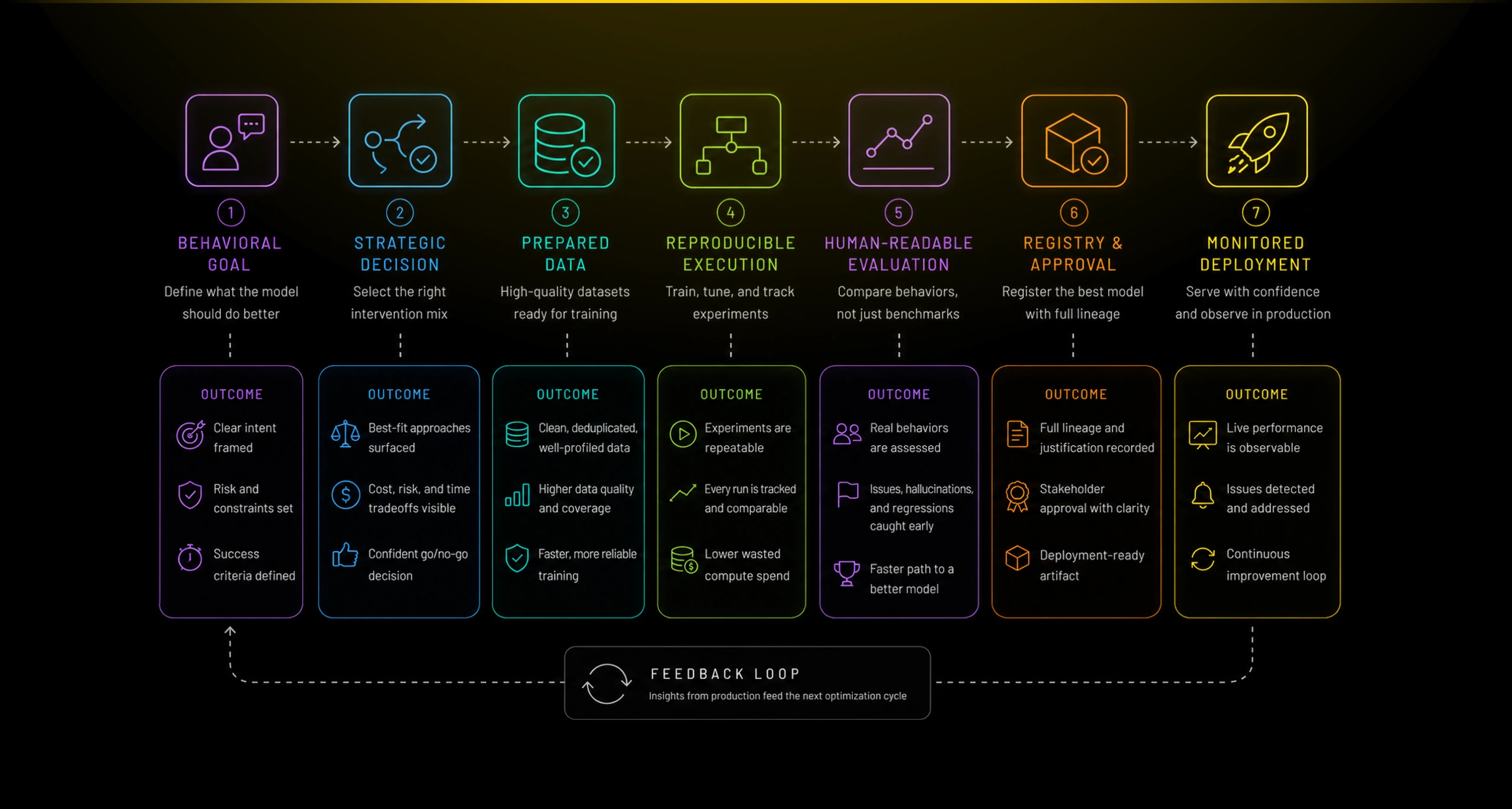
A team can now begin with a behavioral goal, compare plausible interventions, prepare and inspect its data, construct a workflow, preserve every experiment, evaluate outputs against the base model, register the result, and launch it through a guided deployment process.
The resulting MVP demonstrates several practical shifts:
- Optimization strategy becomes an explicit decision rather than a hidden assumption.
- Cost, risk, time, and infrastructure tradeoffs are visible before execution.
- Dataset quality becomes a first-class stage instead of an afterthought.
- Successful and failed runs remain reproducible and comparable.
- Evaluation connects metrics with observable model behavior.
- Deployment preserves lineage and configuration through production launch.
- Technical concepts remain accessible without removing expert control.
These are product-level outcomes demonstrated by the working prototype, not measured customer results. The interface includes representative project data and illustrative evaluation scores to show how the system would operate.
The deeper outcome was a clearer product category. Finetunio began as a guided fine-tuning workbench, but the design exposed a more valuable opportunity: an intelligence layer that helps teams determine how model behavior should change, not merely how a training job should run.
That direction connects directly to my broader work in workflow architecture, orchestration, and AI-native product design. The interface is not decoration around the model pipeline. It is where intent becomes an inspectable, executable system.
The Problem
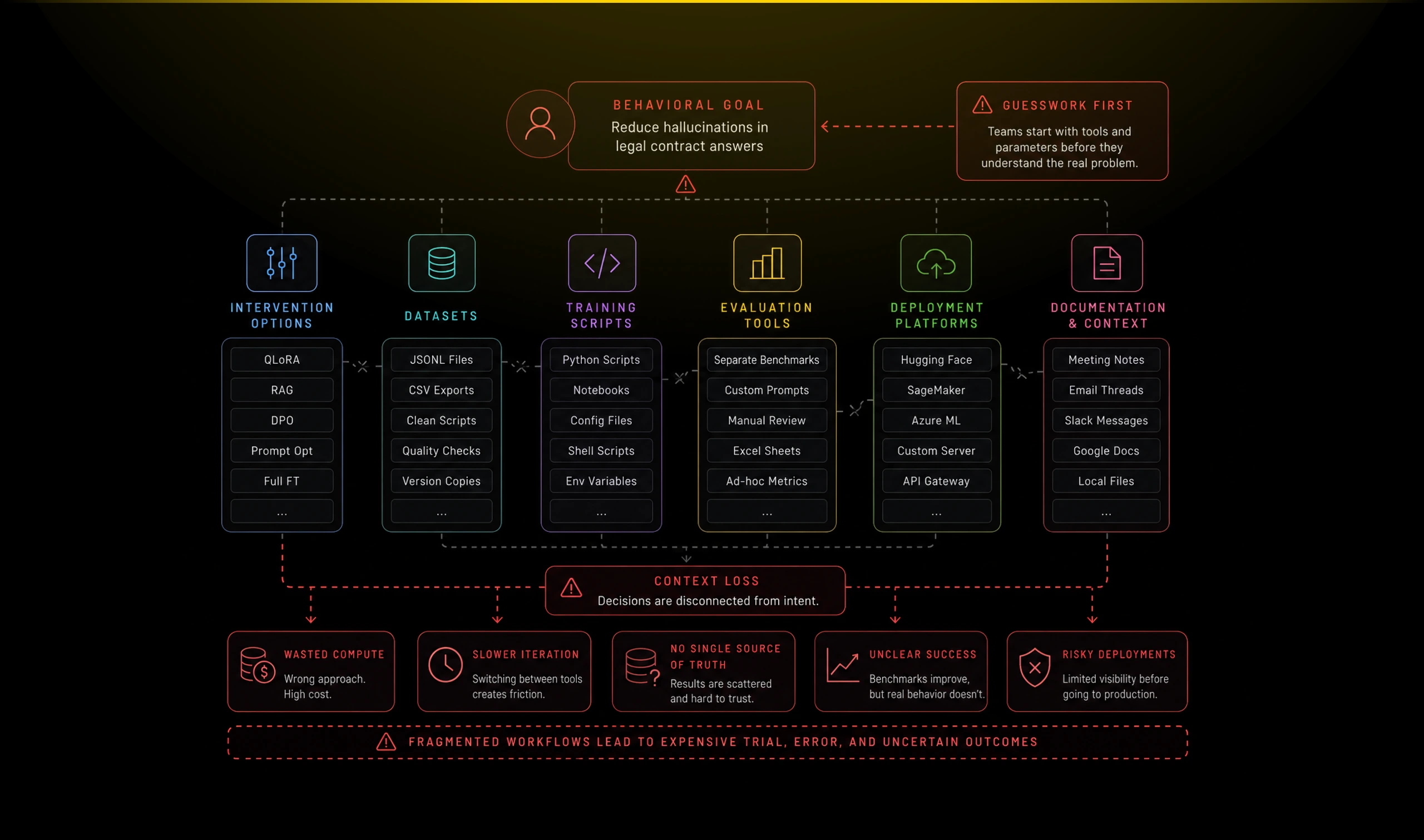
Teams could run training jobs, but choosing the right intervention was still guesswork.
The difficult part of model optimization is rarely starting a training process. It is deciding whether training is the right response to the problem in the first place.
A model may be hallucinating because it lacks current knowledge, follows instructions inconsistently, retrieves the wrong context, produces an unreliable format, or has learned the wrong behavioral pattern. Each diagnosis points toward a different intervention. Fine-tuning, RAG, prompt optimization, preference alignment, tools, and guardrails are not interchangeable.
Yet most systems begin by exposing technical mechanisms. Users are asked to select a framework, configure a learning rate, choose a LoRA rank, and set epochs before the product has established what behavior is actually broken.
This creates an expensive form of trial and error. Teams can consume compute, prepare the wrong dataset, or interpret a higher benchmark score as success while the model continues failing in the situations that matter.
The surrounding workflow compounds the problem. Strategy decisions live in one place, datasets in another, training jobs in scripts or notebooks, evaluation in separate frameworks, and deployment in another operational layer. Experiment lineage and decision context are easily lost between them.
The product therefore had to solve two related problems: translate human intent into a defensible optimization decision, then preserve that reasoning throughout execution.
Solution
Designing the missing decision layer between intent and execution.
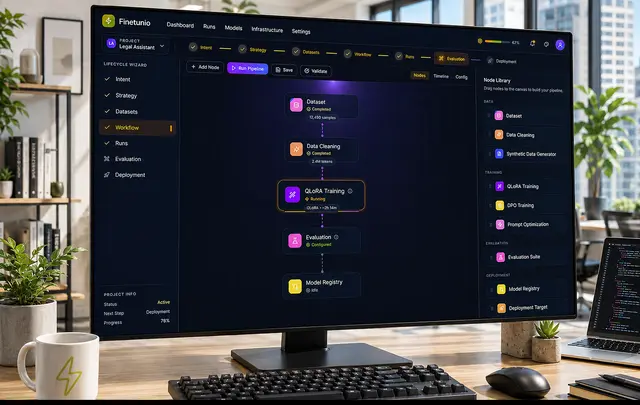
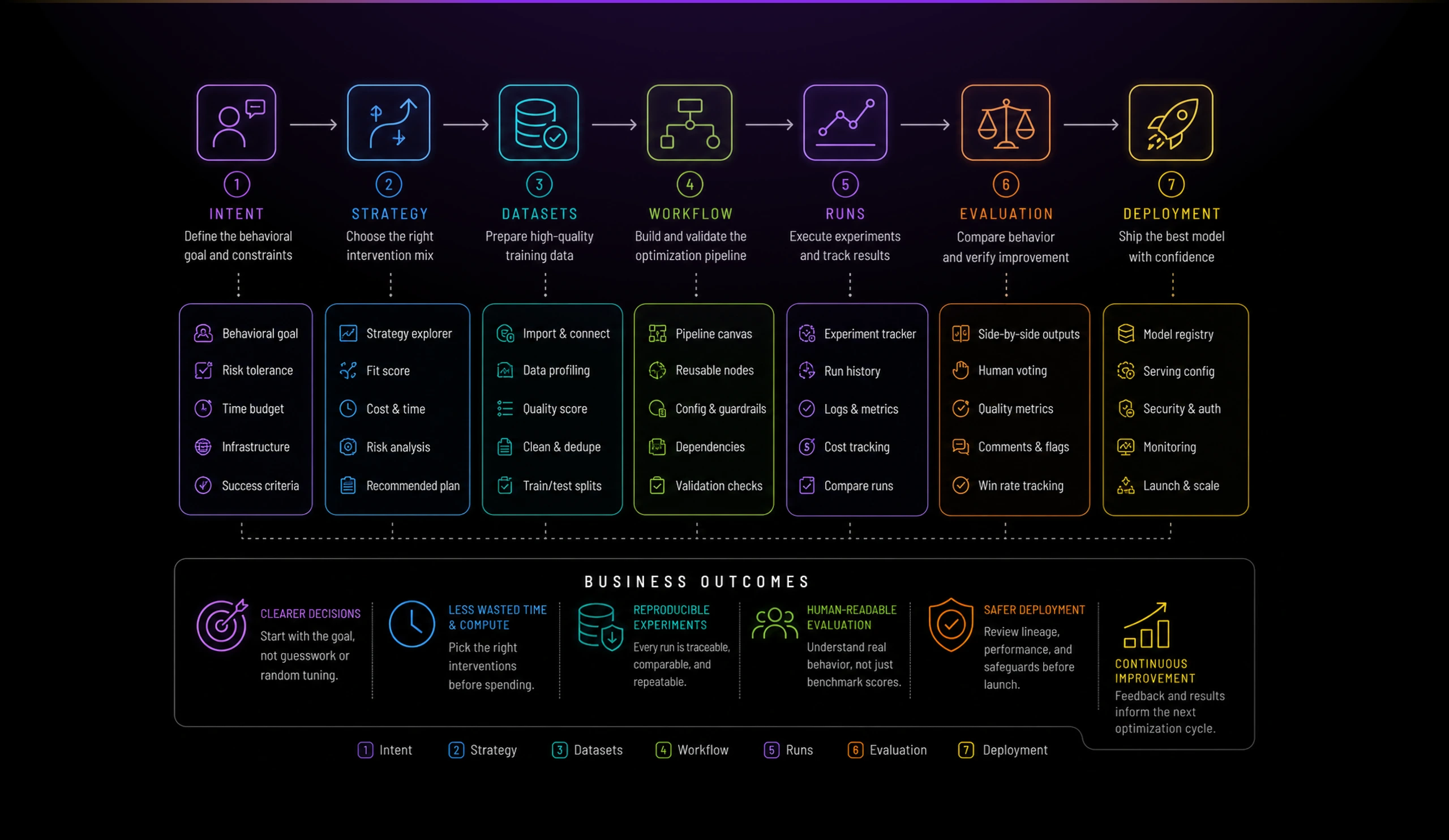
I structured Finetunio around a seven-stage lifecycle:
Intent → Strategy → Datasets → Workflow → Runs → Evaluation → Deployment
This lifecycle became the product’s primary mental model. It prevents optimization from being treated as an isolated training job and keeps each decision connected to the goal that produced it. The project state is driven by actual progress data rather than by whichever screen the user happens to be viewing.
Starting with the outcome, not the parameters.
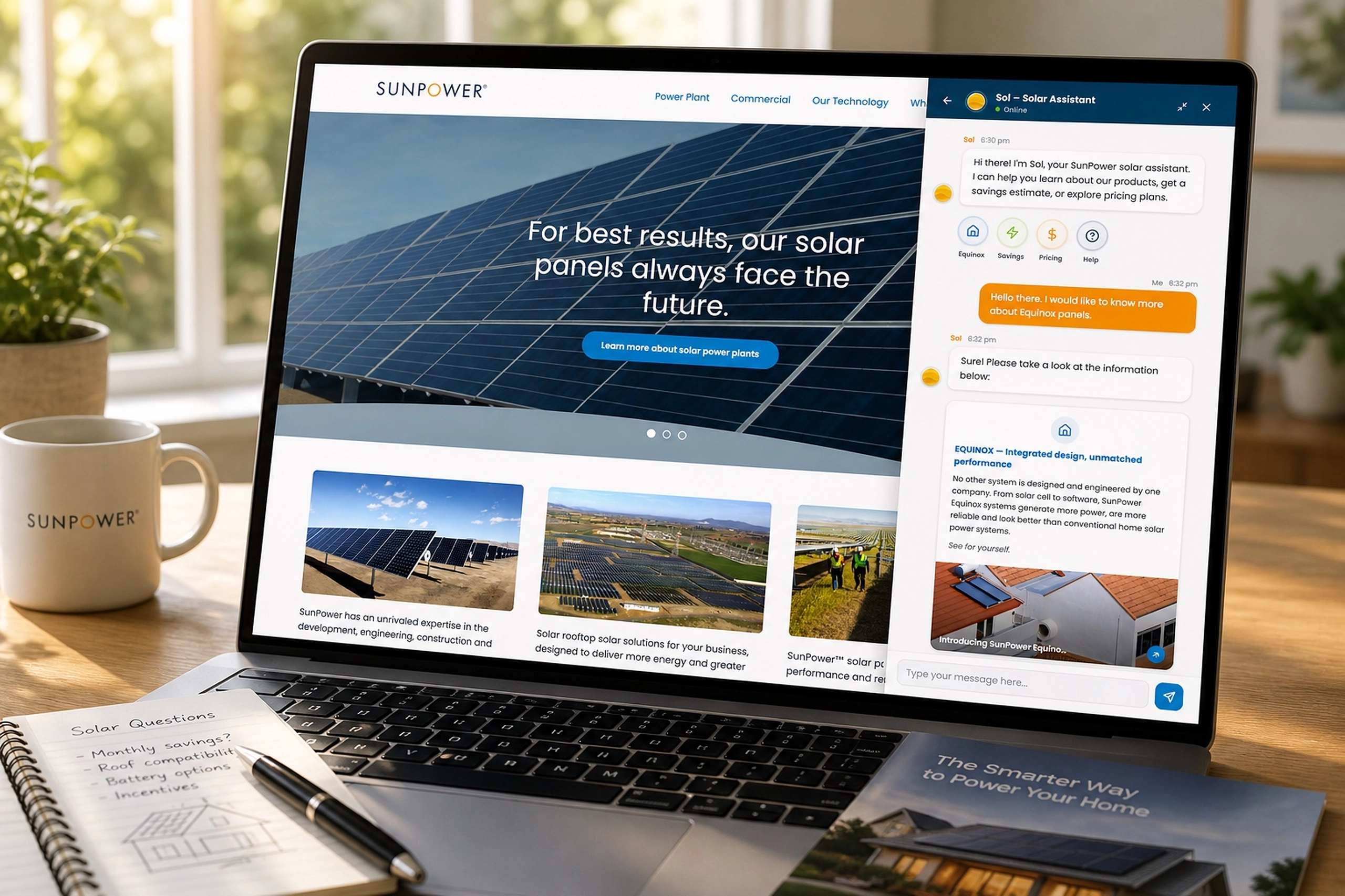
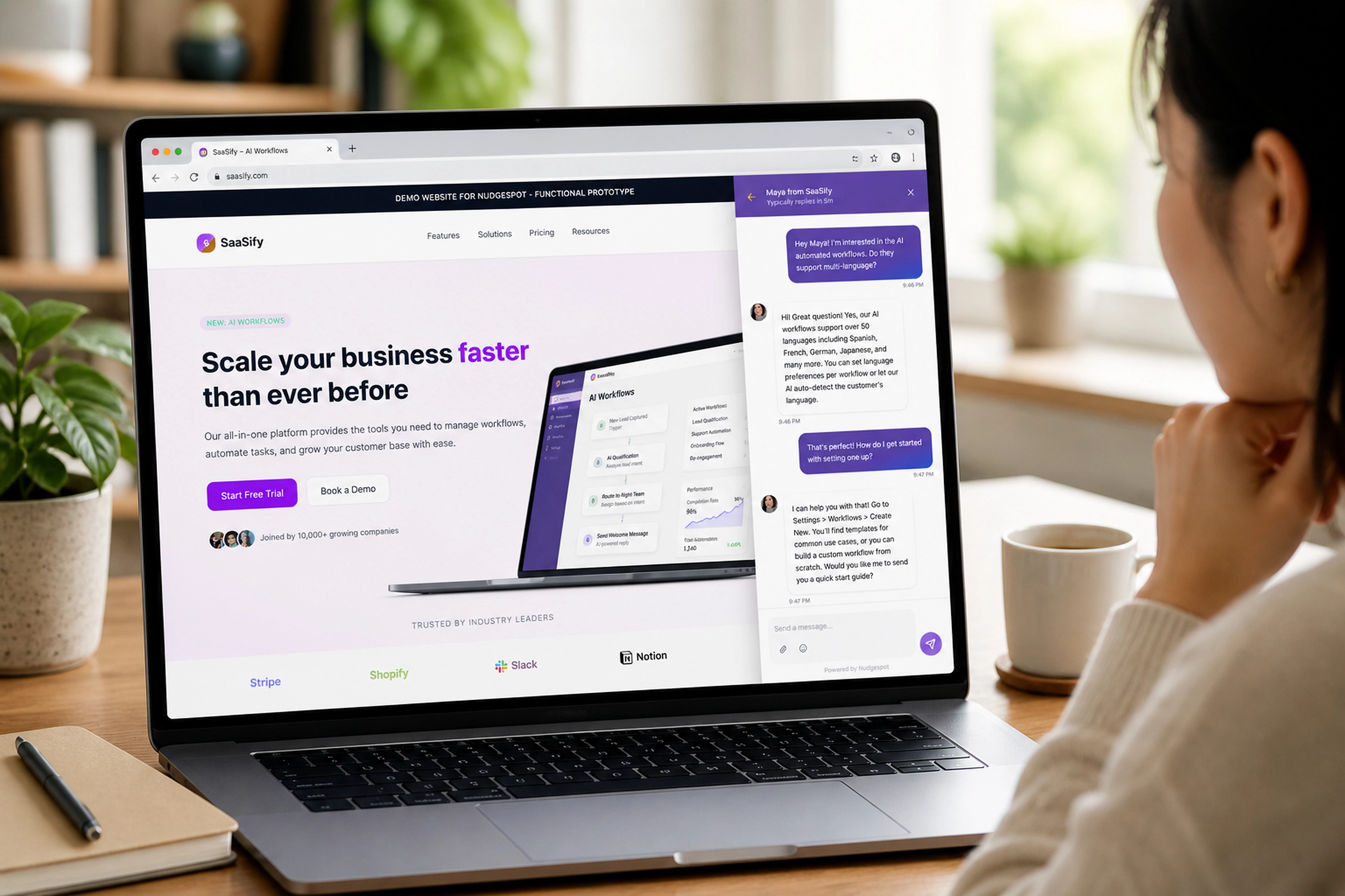
The Intent Builder asks users what they need the model to do better, how much risk they can tolerate, and what infrastructure and time they have available.
Instead of forcing users to begin with “LoRA rank” or “learning rate,” the experience begins with goals such as reducing hallucinations, improving reasoning, increasing domain knowledge, or producing more reliable structured outputs. This reflects the broader UX principle behind the product: declare the desired behavioral change first, disclose implementation complexity only when it becomes useful.
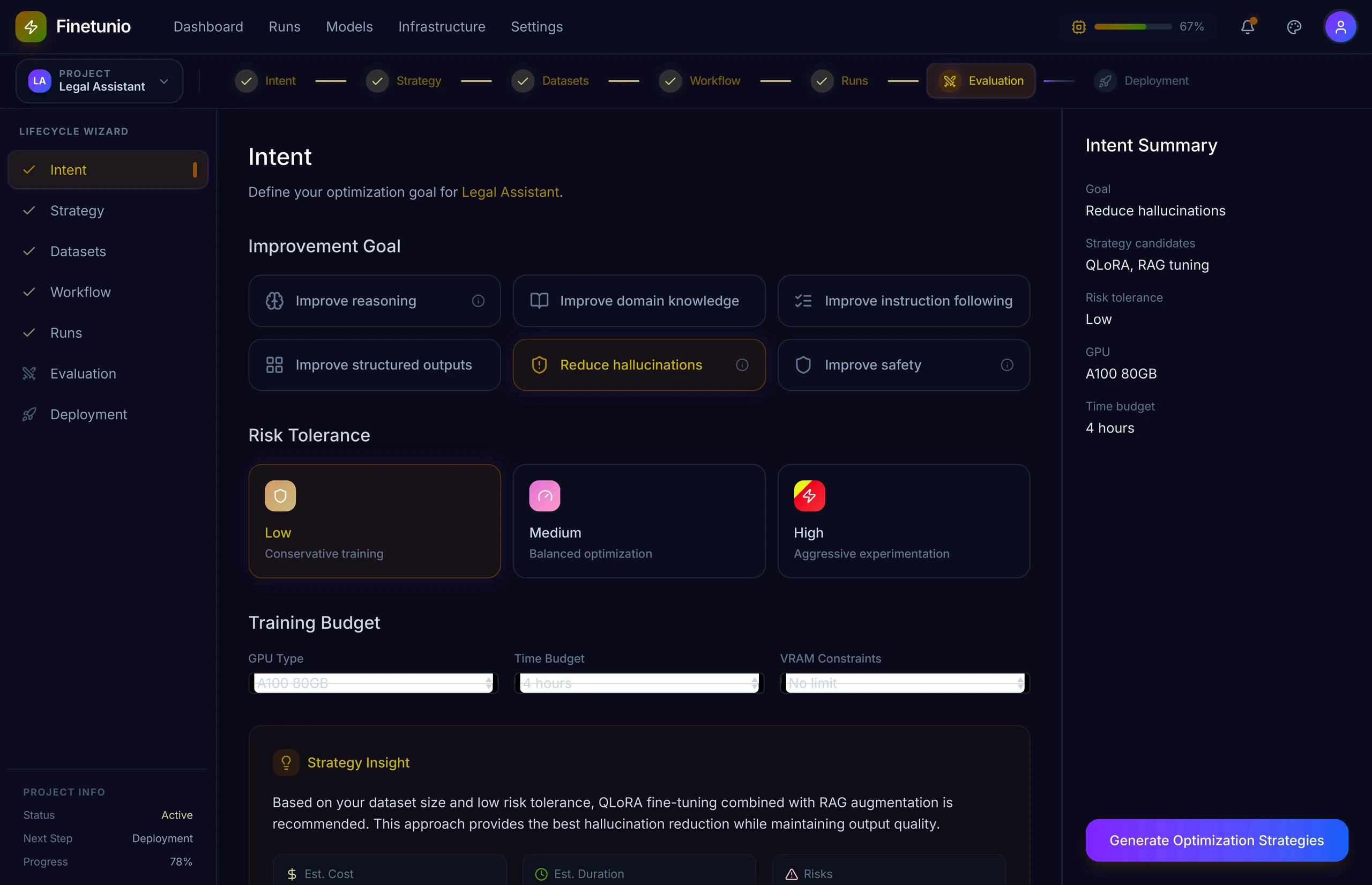
The right-side summary keeps the emerging intent visible while the system identifies candidate strategies. That persistent context is important because the strategy should remain traceable to the goal, not become a detached configuration exercise.
Converting technical alternatives into decision support.
The Strategy Explorer compares optimization approaches through expected fit, cost, risk, duration, and infrastructure requirements.
I used a cost-versus-performance visualization to make tradeoffs legible before asking users to commit. The accompanying table preserves the detail needed by technical users, while recommendations, scoring, and contextual explanations keep the experience accessible to product leads and team members who do not specialize in model training.
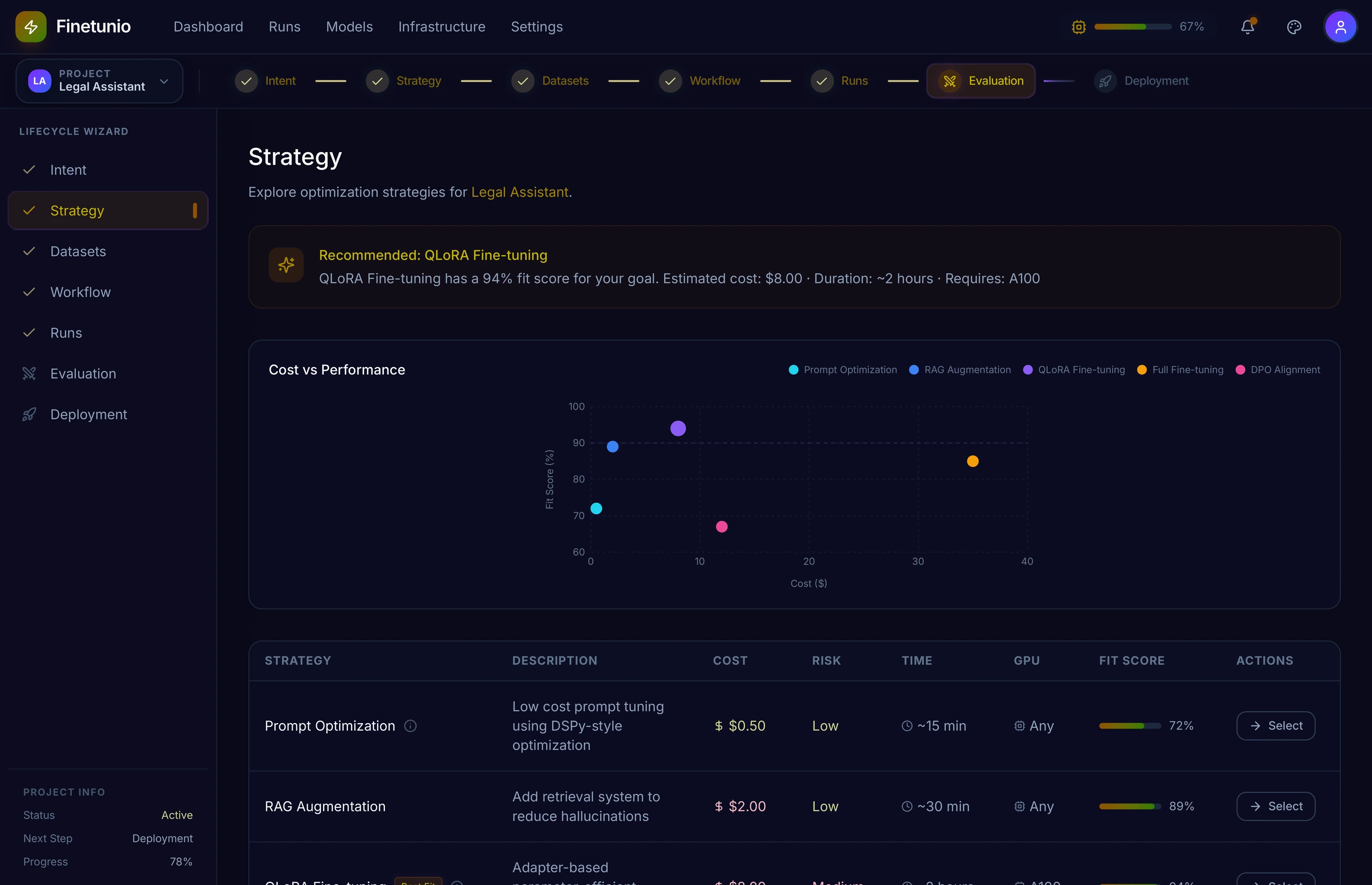
The current MVP recommends individual strategies including prompt optimization, RAG, QLoRA, full fine-tuning, and DPO. The larger product direction extends this into an Optimization Decision Engine that diagnoses the failure pattern and composes several interventions when necessary.
For example, reducing hallucinations may require RAG first, prompt optimization as a quick secondary layer, and light QLoRA only if a deeper behavioral change remains necessary. The system should also be able to explain why fine-tuning is not recommended.
Making the optimization plan visible and executable.
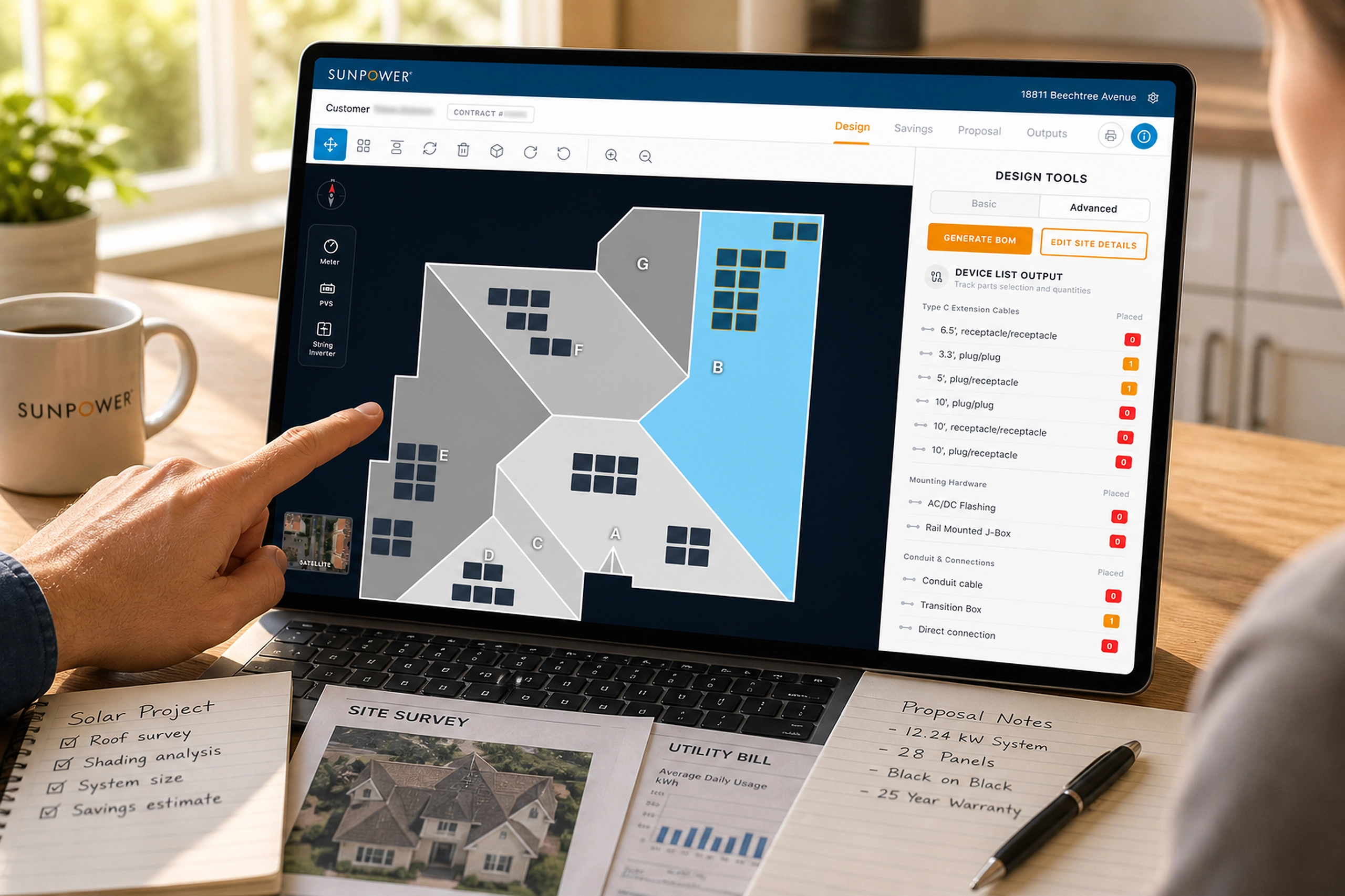
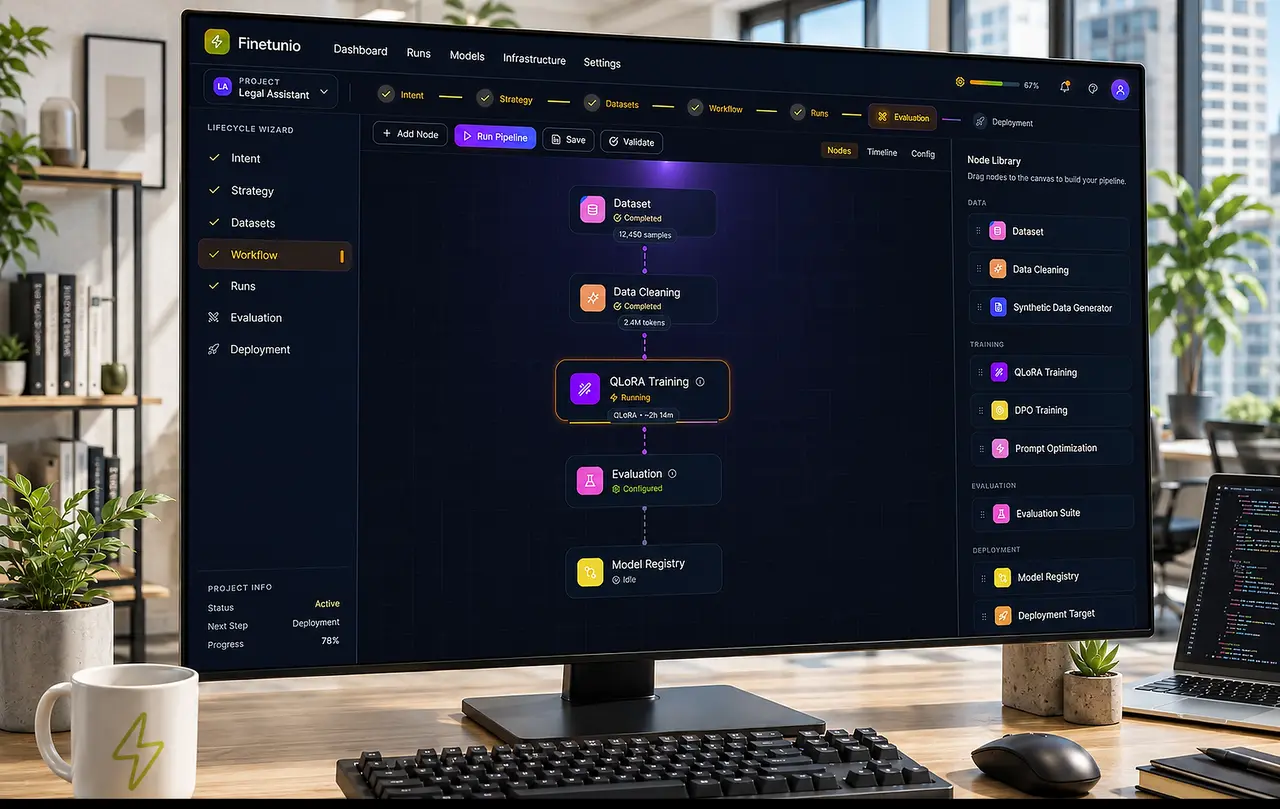
Once a strategy is selected, the Workflow Canvas converts it into a visual pipeline.
I designed the canvas to sit between an abstract recommendation and the underlying execution system. Users can inspect data preparation, training, evaluation, and model registration as connected states rather than treating each as an unrelated tool or script.
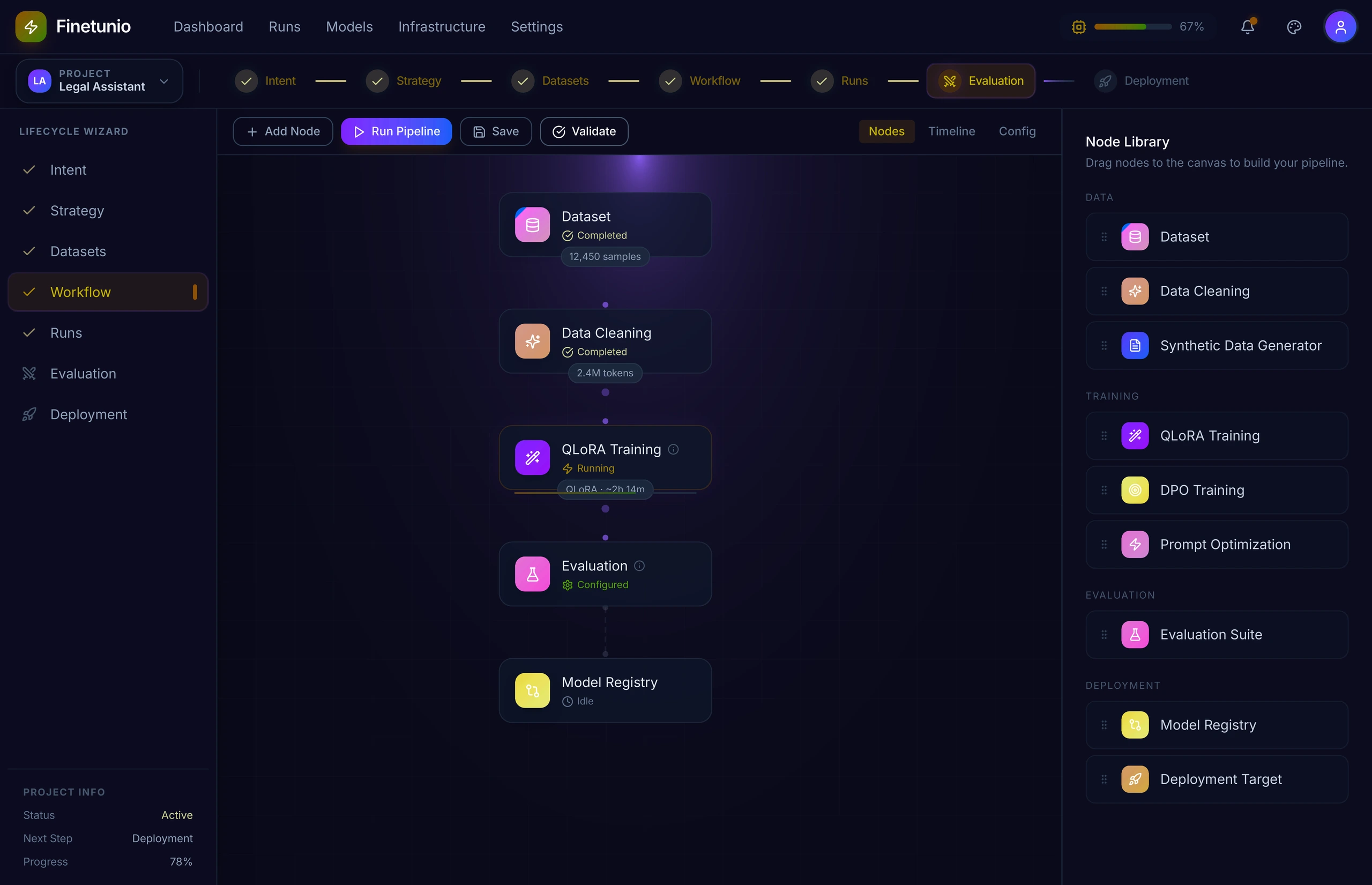
The canvas maintains technical depth without presenting all of it at once. Each node can expose configuration when selected, while the main view remains focused on sequence, status, dependencies, and execution progress.
The important decision was not to hide complexity completely. Model optimization is too consequential for a deceptive one-click abstraction. Instead, I used progressive disclosure to make the default experience understandable while preserving the parameters, validation, and execution state experts need.
Treating experiments as evidence, not disposable runs.
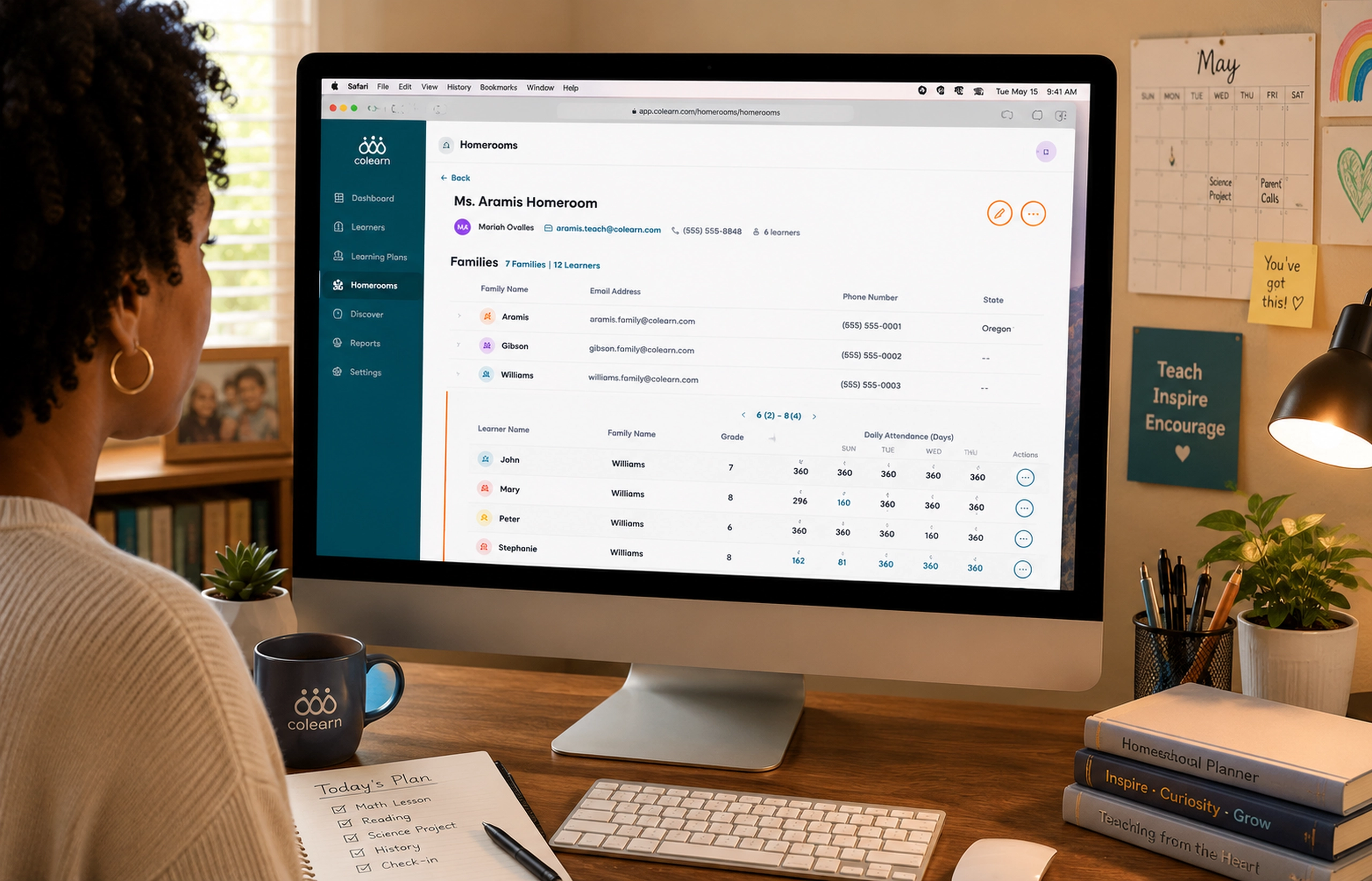
The Runs experience records the strategy, model, dataset, duration, status, cost, evaluation score, configuration, logs, and output artifact associated with every experiment.
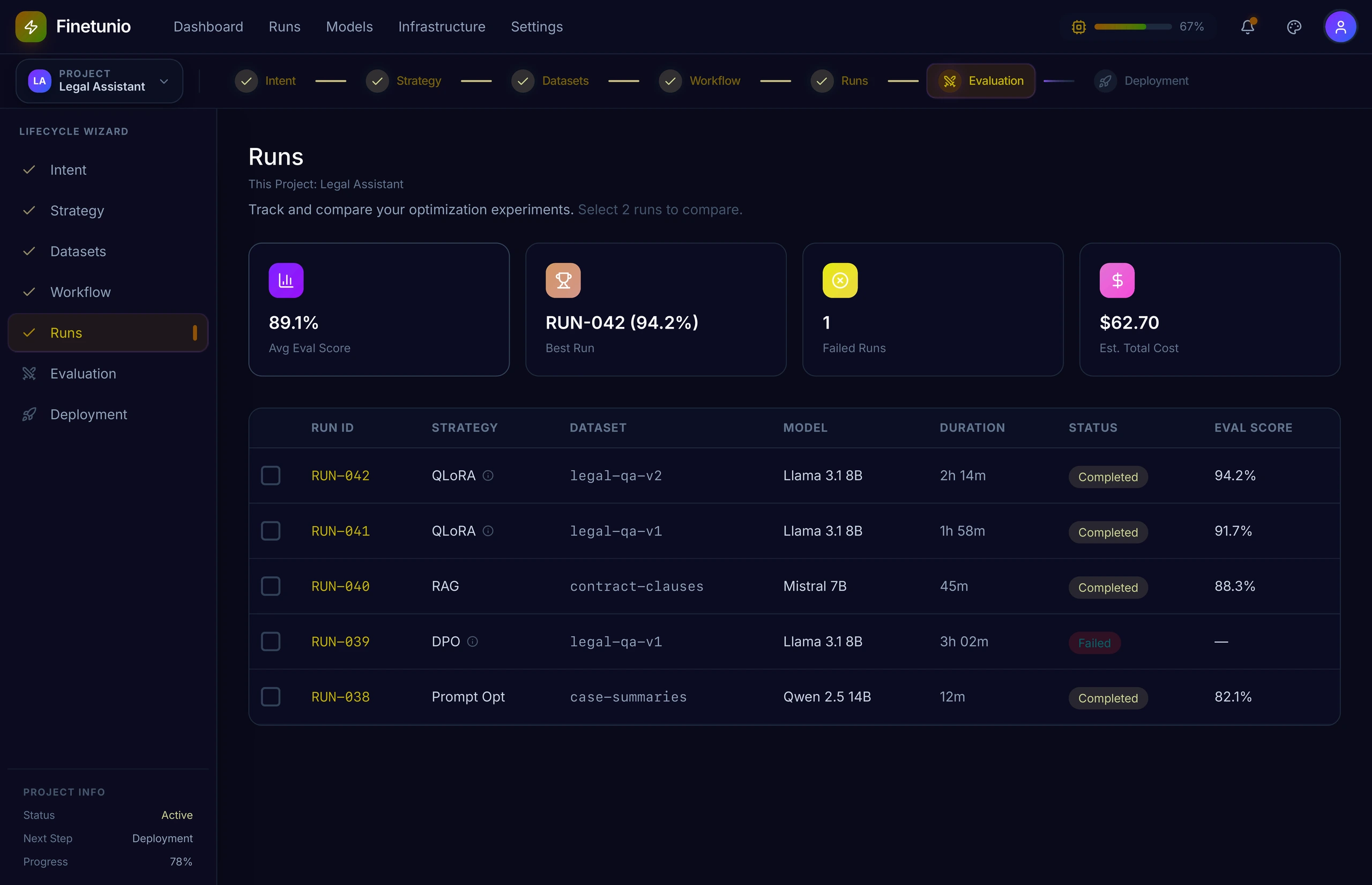
Users can inspect individual runs and compare two experiments directly. This changes the workflow from “try another configuration” into a reproducible process where teams can identify whether an improvement came from the dataset, training configuration, intervention type, or model choice.
Evaluating behavior where humans can understand it.
A higher aggregate score does not guarantee that the model changed in the desired way.
The Evaluation Arena therefore compares the base model and optimized model side by side using real prompts. It combines relevance, accuracy, completeness, citations, human voting, flags, comments, prompt history, and win rates.
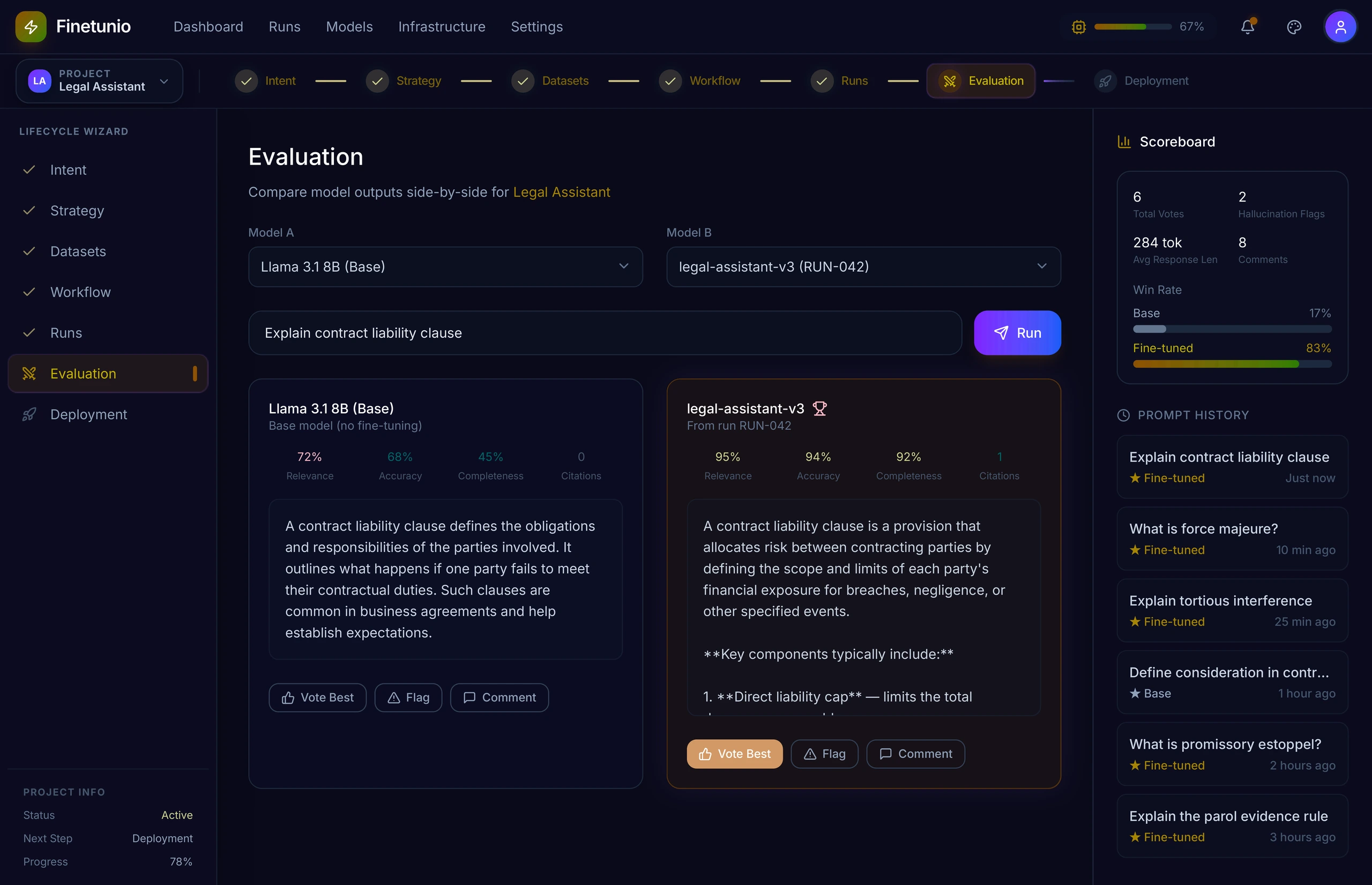
This makes evaluation more interpretable and creates an auditable record of why one model was preferred. It also provides the foundation for future automated behavioral evaluation, regression detection, boundary testing, and feedback loops that revise the optimization plan.
Carrying the decision through deployment.
I designed deployment as the final stage of the same lifecycle rather than a separate administrative task.
The workflow supports Hugging Face, local inference, managed REST endpoints, SageMaker, Azure ML, and Vertex AI. Before launch, the user can review model lineage, target configuration, quantization, precision, concurrency, authentication, monitoring, latency, throughput, cost assumptions, and preflight checks.
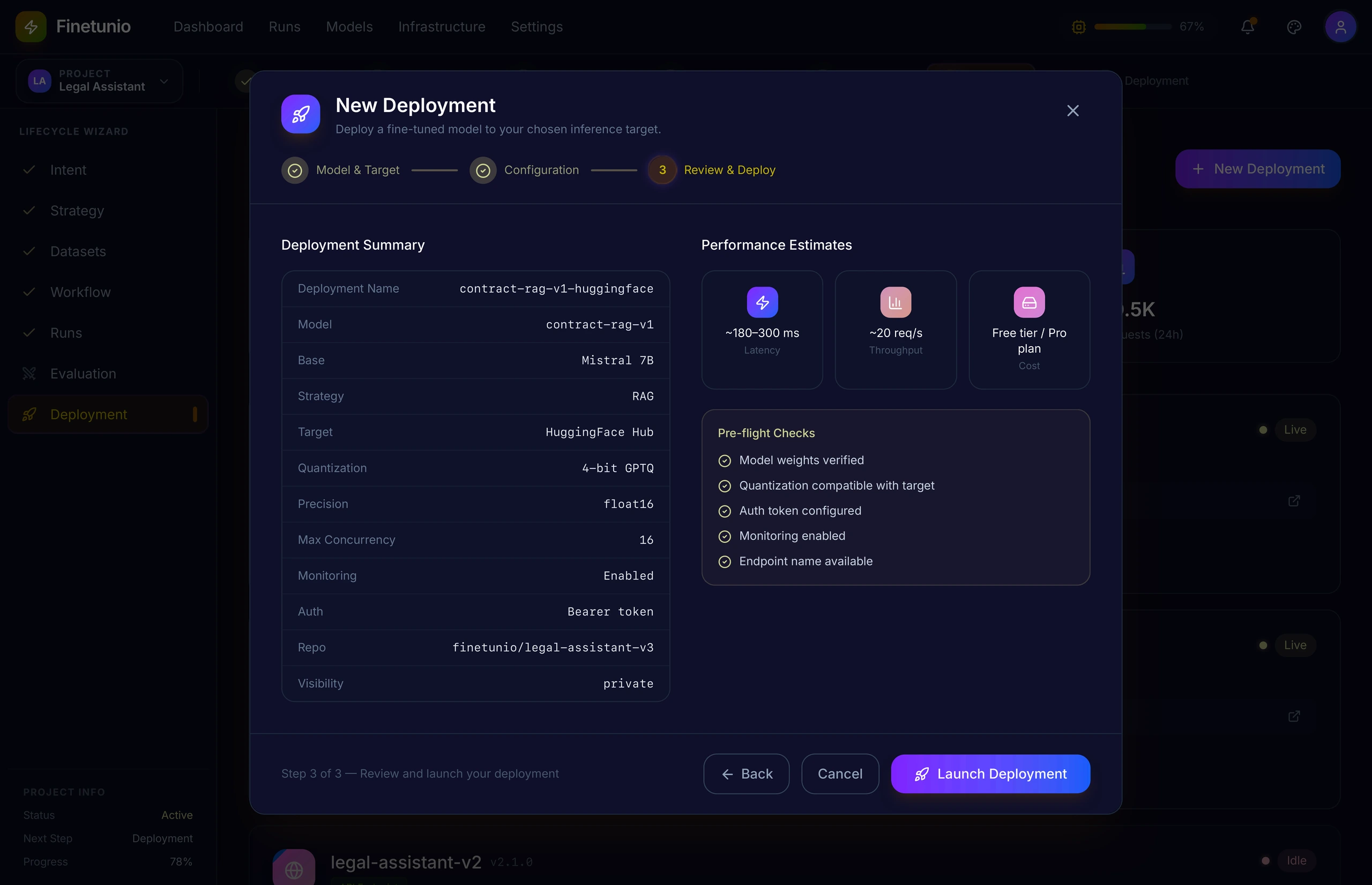
The underlying execution backend can change, but the human-facing decision path remains consistent. That separation between intent and execution is central to the product architecture and its long-term ability to support multiple optimization and serving systems.